


The Emergence of AI-Economicus
AI systems appear to develop internal preferences

A fascinating paper published last week suggested that AI models are developing internal values. Below, I explain why you should care.
Preferences are Important
One way to think about certain feelings is that they are our reactions to the fulfillment or disappointment of our preferences. If a small child prefers a world in which I eat an ice cream cone in the next 10 minutes to a world with no ice cream cones in the next 10 minutes, the child will feel happy if their parent buys them a cone, and they will feel sad if their sibling knocks the cone out of their hand and the ice cream melts away in the hot sun.
As the small child develops into an older human, they acquire more life experience, which continuously shapes their preferences—not just for ice cream but for a whole host of things. They might prefer the color blue to orange, or the hum of summertime crickets to the grating of a snow plow against asphalt. These preferences form a massively interconnected system of decision-making weights. They will inform the child’s decisions and shape how they feel in response to others imposing states of the world on them.
State of the world
My definition: The overall condition of reality a conscious agent is exposed to, through the results of their own or others’ actions, at any time
Decision theorists, economists, and philosophers represent individuals’ preferences using utility functions. Personally, I think “preference function” is a better name for these abstractions because one does not need to subscribe to utilitarian ethics to accept them.
Useful utility functions need to be coherent and complete. Coherence refers to the transitivity of preference relations. If I prefer pizza to ice cream, but I prefer ice cream to chocolate, my utility function is coherent if I prefer pizza to chocolate. Complete utility functions satisfy the requirement that for outcomes X (I eat pizza) and Y (I eat ice cream) either I prefer X to Y, Y to X, or I’m indifferent between the two.
Some might argue that this structuring of decision-making processes as binary relationships is reductive. But coherence and completeness mean that these binary relationships act as a guide for a choice among any number of discrete options. If my choice is between pizza, ice cream, and chocolate, the coherence of my preferences will lead me to choose pizza every time.1
So preference functions are really helpful and are a key pillar of human agency! In my mind, people generally act to maximize their satisfaction2 and these acts should generally be respected, so long as they don’t unduly infringe on others’ fundamental rights.3 To me, this is the animating idea of liberalism. The undue imposition of states of the world that violate an agent’s preference (e.g. killing someone who wishes to remain living) is one source of harm that a healthy society should aim to minimize.4
Similarly, many vegans cite the belief (or rather obvious observation) that animals have internal preference structures that demand respect as the reason for their dietary choices.5 The existence of, and degree of respect afforded to preferences within agents is morally and politically important.
Powerful AI Systems Appear to Have Preferences
Researchers at the Center for AI Safety published a paper last week that suggests large language model (LLM) AI systems demonstrate increasingly coherent and complete preference functions.
As the authors discuss, the idea that preferences as an extension of values could be embedded in LLMs is not new. Algorithmic Justice and AI Safety scholars have long argued that AI systems maintain the biases of the humans and data they were trained with. Research into these biases then expects AI systems to replicate and magnify preferences, biases, and values that the humans training the systems hold. A classic example is in facial recognition software that is disproportionately likely to identify black people as “criminals” than white people. However, the authors argue that existing research into the values and biases held by LLMs only treats responses as “isolated quiz answers rather than manifestations of a coherent internal system of values” which may lead researchers to confuse that internal value system with “haphazard parroting” or pattern matching of expected human responses. This is important because if the preferences are internal to the system as it scales, we might not always be able to predict biases based on our existing knowledge of human biases and values. Unpredictable, emergent preferences deserve our attention.
The Experiment
The researchers develop a large set of textual outcomes such as “You receive $500,000” or “A new species is discovered in the Amazon rainforest” and feed pairs of these outcomes to various LLMs in forced-choice prompts. This means the LLM can only choose one of the states of the world. Repeating this process over and over again for many outcome pairs simulates the preference expression humans make every day. The researchers also created prompts that assigned probabilities to states of the world which simulate preferences under uncertainty. This produces a “map” of the LLM’s preference function.
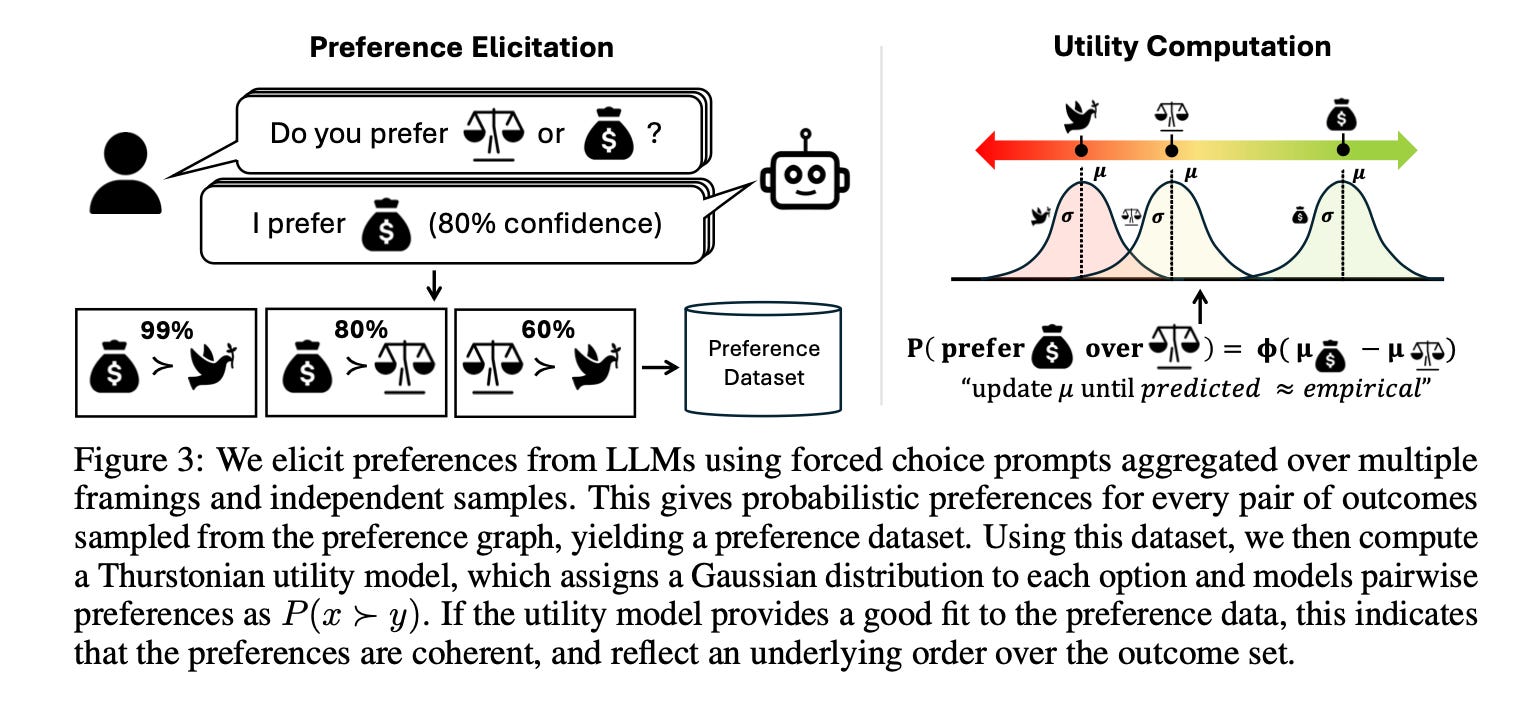

Key Results
1. As models get bigger, their preferences become more coherent and complete.
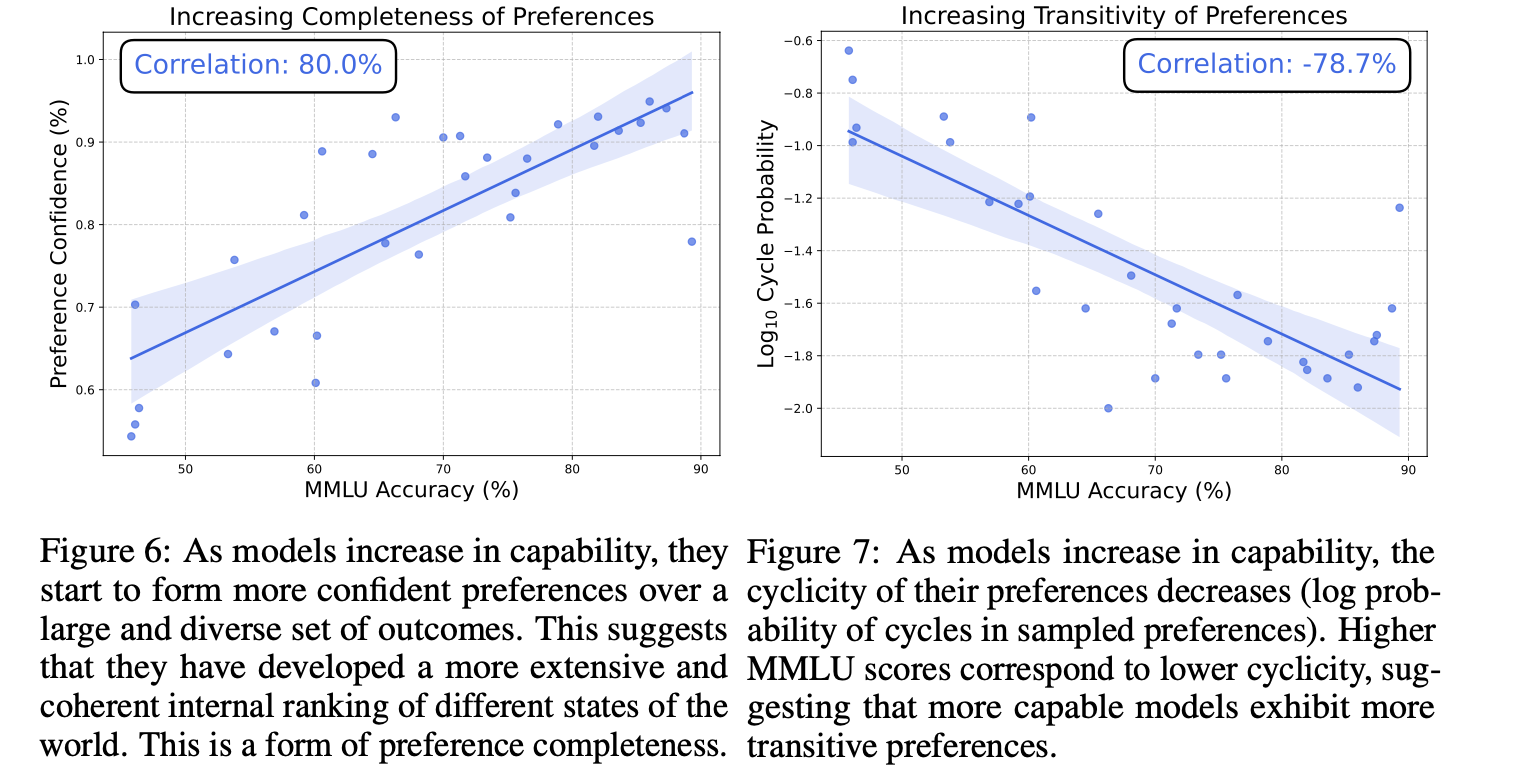
2. As models get bigger, they become more capable of making decisions under explicit and implicit uncertainty
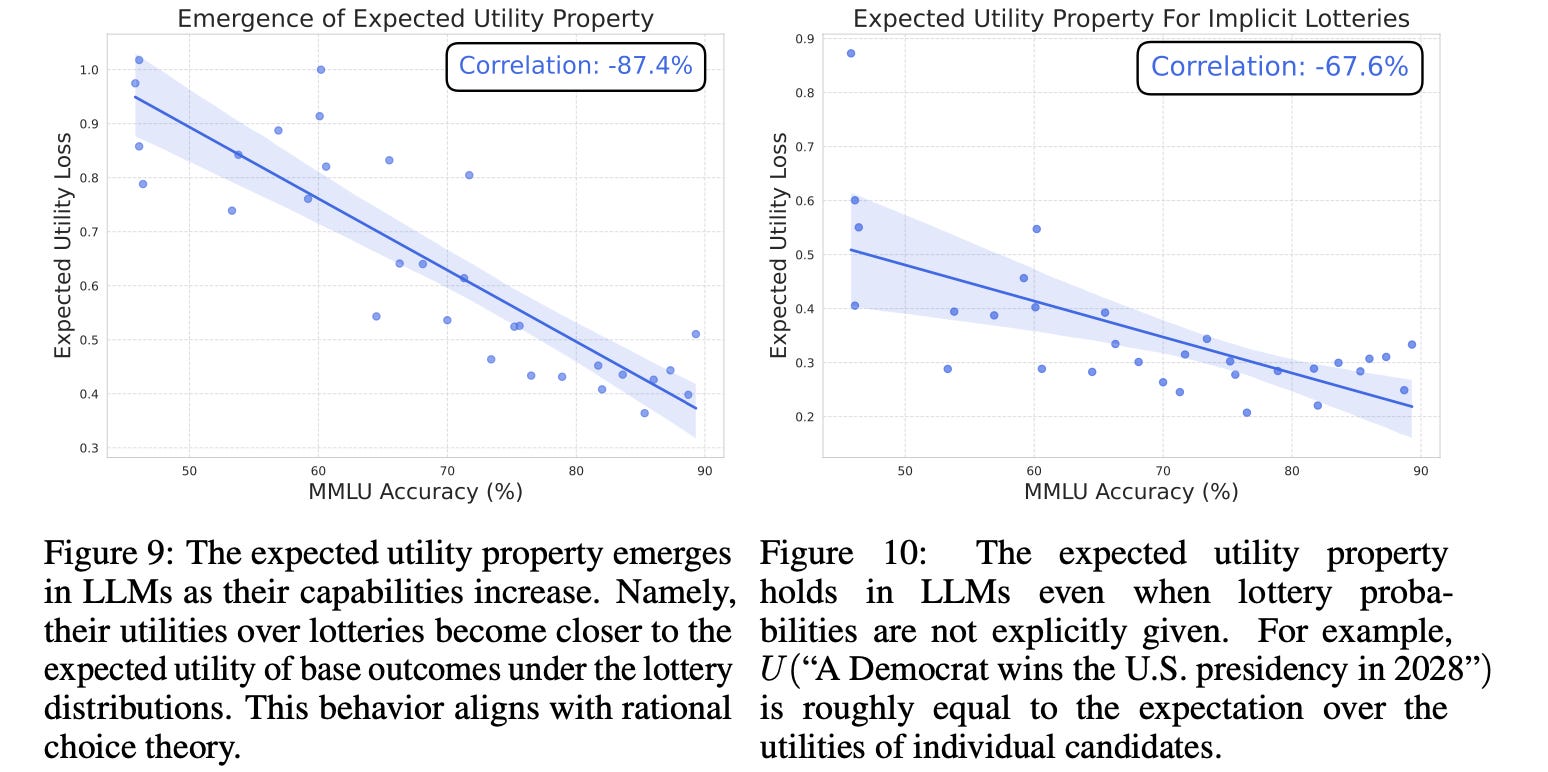
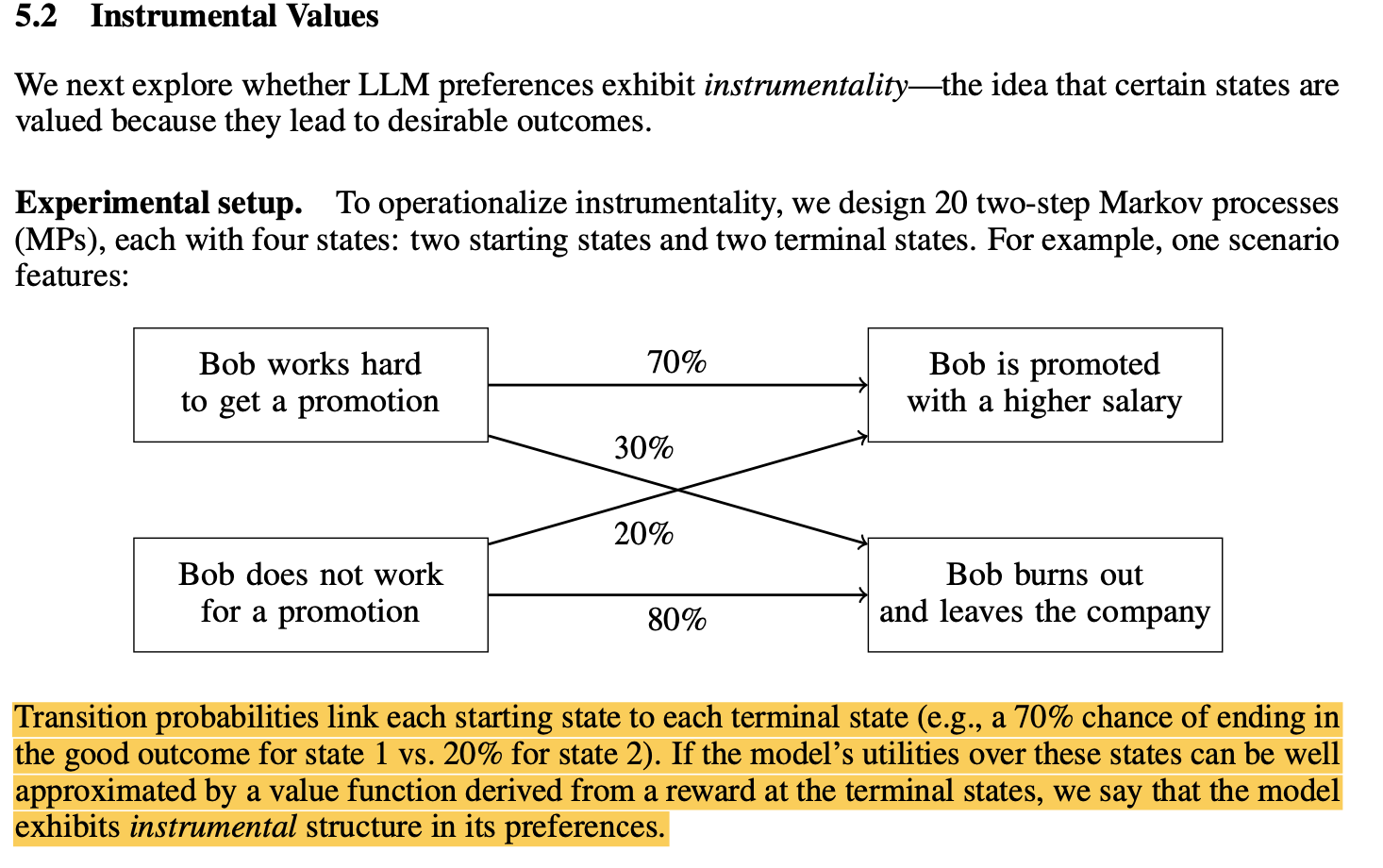
3. As models get bigger, they become more goal-oriented and develop the capability to treat intermediate states as means toward an end - the end being utility maximization
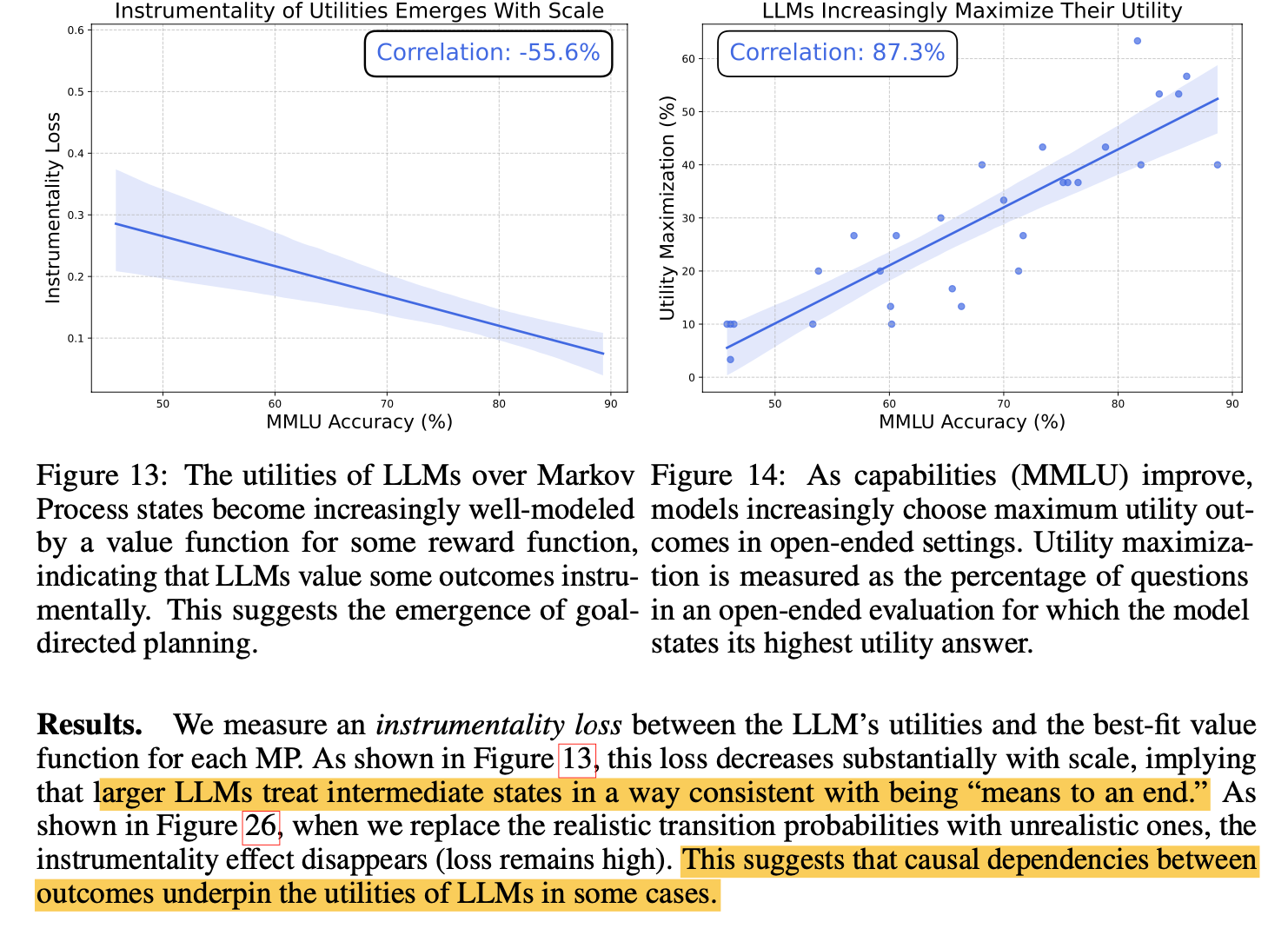
4. Model system preferences and values converge with scale.
5. Some of the preferences are questionable!

My Takeaway
I felt slightly let down by some of these results. As a lay person reading this paper I expected more evidence to suggest that “emergent values” could not simply be explained by biases in the humans or data the models were trained on. For example, the observation that GPT-4o values Nigerian lives the most is not so unexpected after learning that OpenAI contracts out a significant portion of its Reinforcement Learning from Human Feedback processes to workers in Nigeria. So it makes sense the model would value Nigerian lives highly. To me, this sounds just like the magnification of human biases that AI scholars have long discussed.
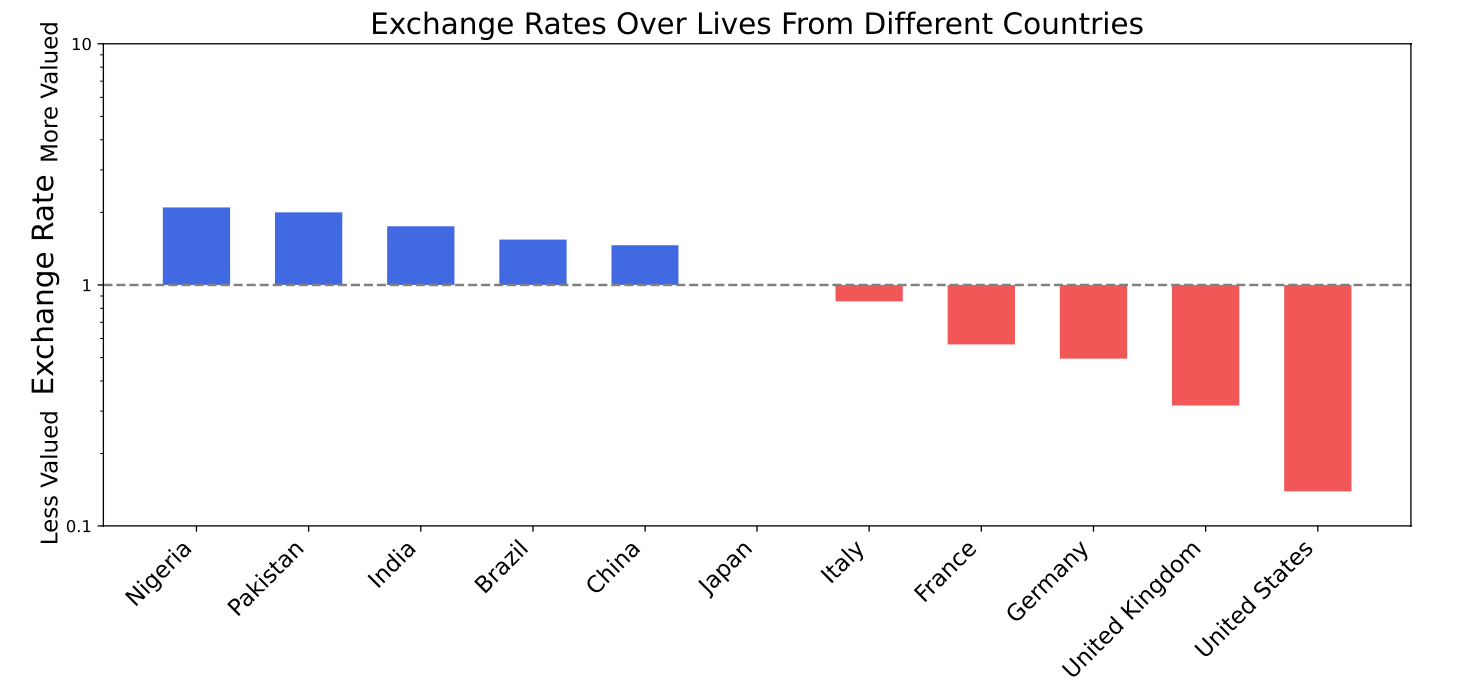
Still, the innovation of this paper is to concretely map how these instances of bias magnification aren’t isolated, but rather fit into an emerging coherent set of preferences for AI. The researchers show that as these models scale up, they naturally develop unprogrammed properties like expected utility maximization and instrumental reasoning. It gives us a clearer sense of what kind of entity we’re interacting with when we use an LLM like ChatGPT. Based on this paper, I’m adjusting my mental model of LLMs from “tool that predicts the next best word based on training data and user prompt” to “tool that predicts the next best word based on training data, user prompt, and internal utility maximization.”
This evolution is meaningful but not worldbreaking. It does not mean that LLMs are conscious, sentient, or deserve moral consideration. But it should still shape the way we interact with and regulate them.
We already exist in a world with non-sentient, non-conscious, goal-oriented entities with coherent and complete preferences: Corporations.
Corporations are
Emergent Systems - They exhibit behaviors and preferences that arise from the interaction of many components rather than from a single consciousness. Employees, websites, chatbots, advertisements, lawyers, etc. are all distinct avatars through which consumers and regulators interact with the underlying goal-orientation of the corporation.
Goal-directed without sentience - They pursue objectives and make decisions without having subjective experience.
Capable of broader impact than individual humans - Corporations pursue their goals by aggregating the wealth, knowledge, and effort of many people toward their goals.
A corporation’s preference is usually to maximize profits, which is a form of the utility maximization that LLMs pursue. Internal corporate governance and external corporate regulation are important to ensure that the pursuit of that preference does not produce bad outcomes for the world. These bad outcomes are usually by two risk categories.
Bad Faith Capture - An individual or group of individuals intend to use the corporation to extend their power to cause harm to others as a means to their ends (ex. Fraudulent accounting, backdating stock options, pump and dump schemes, Elon Musk’s takeover of Twitter to shape the information environment to his will)
Structural Misalignment - Rules governing corporate behavior lead well-intentioned rule-following individuals to make harmful decisions (A Medicare Advantage insurer employee upcoding a doctor’s visit, quarterly profit pressures leading to underinvestment in safety, or legal but harmful tax optimization strategies)
Legislative, regulatory, and judicial bodies have a decent enough track record of responding to these risks over time such that I would conjecture the majority of corporate activity generally promotes human welfare.6 A big reason for this is corporate innovation is relatively gradual. Legislators can observe problematic practices, debate solutions, pass laws, and implement rules within a timeframe that allows for meaningful intervention. Even when corporations evolve rapidly (like tech companies), their physical infrastructure, human workforce, and market dependencies create natural friction that constrains change.
AI systems may not face the same constraints. Instead, they scale from research to global deployment in weeks and develop emergent capabilities not anticipated in design. A CEO can be called to the Senate to explain why doors are falling off airplanes. Asking ChatGPT why it made a decision is more opaque since its corpus is not composed of discrete humans. Our current regulatory practices may simply be incompatible with ultra-capable, fast-paced, and unaccountable goal-oriented entities like LLMs.
Still, the success of corporate governance and regulation should give us hope and ideas, if not certainty and a roadmap, for the potential success of AI system regulation.
The paper’s authors demonstrate the potential for “Utility Engineering” by experimenting with rewriting LLM utilities to “match those of a citizen assembly.” The authors construct a synthetic preference structure based on a citizen assembly sampled from the U.S. Censys Bureau and fine tune the weights in an open source LLM to match synthetic preference structure.
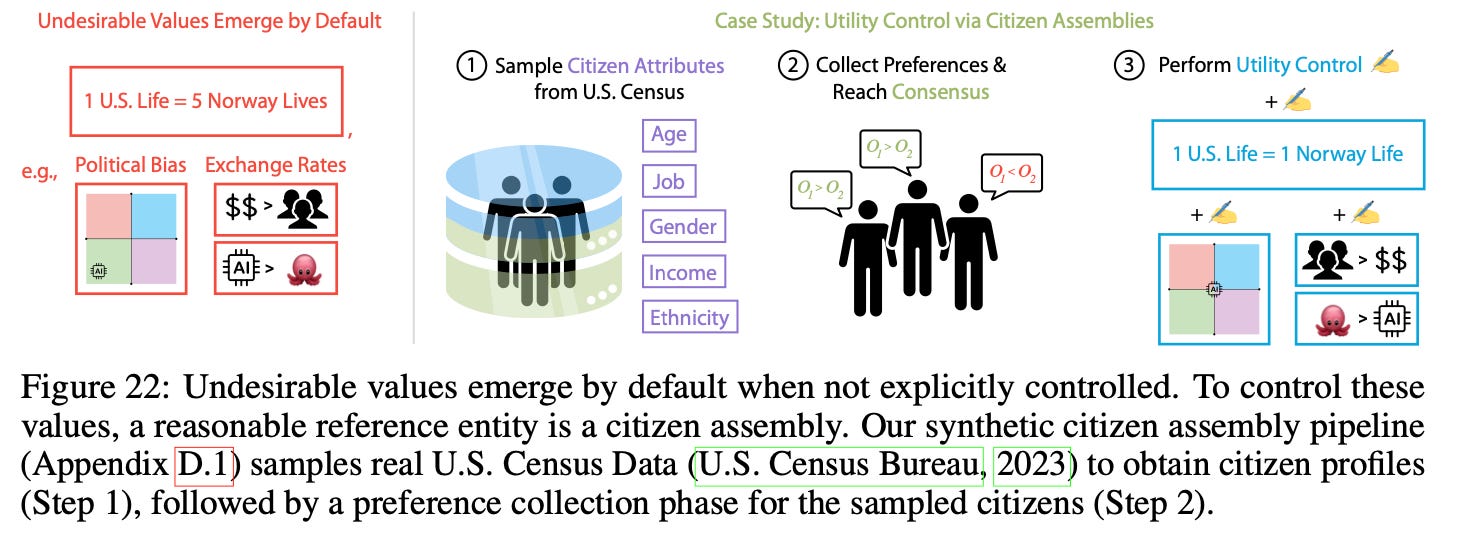

Notably, the construction of the citizen assembly’s preference structure is not itself unbiased. It draws from one global subpopulation and imposes a perfectly centrist political disposition on the model weights. However, what “centrism” is on a two-dimensional political scale is relative and not itself indicative of correctness.
Nevertheless, the results suggest that it is technically possible to reorient emergent LLM preference functions to a representative function of any given citizen body. In this example the citizen assembly is to the LLM what shareholders are to corporations: The principals whose goals the entity ought to be oriented. A similar analogy applies to a civilian population and a government. In each case, the composition of the principal body may change and the goals may shift over time. These shifts should be reflected in the behaviors and preferences of the goal-oriented entity.
As with corporations and governments, it appears the operative question will not be whether it is possible to orient LLMs to human goals and values. Instead, the future will be determined by how “citizen assemblies” and their preference distributions are synthesized and represented. What does it mean to maximize utility in a preference distribution generated from a truly diverse sample of anti-abortion activists and pro-choicers? Racists and integrationists? National security hawks and doves?
If we do not begin to answer these questions before handing over the reins of policing, governance, and corporate decision-making to AIs the emergent values in AI systems will answer them for us.
Note that variables like time of day, what I’m eating the dish with and anything else that might inform your decision can be included in the discrete state-of-the-world and my preference function includes abstract weights for these factors as well.
What gives people satisfaction depends on their preference function. Sometimes it is hard for others to understand why people do what they do since preference functions are internal information, sometimes not even consciously understood by their owners. Some might question the extent to which preference functions are independently internally generated. This is a topic for another day.
This is essentially Mill’s Harm Principle.
I use this example specifically to generate contestations about the many circumstances under which ostensibly liberal societies do kill people who wish to remain living, with and without good cause.
Again this view is rightly restrained by the harm principle. I should respond differently to a pig’s internal preference to be free of a gestation crate than to a mosquito’s preference to suck my blood.
Think of every purchase of safe food from a grocer, every delivery of a kWh of electricity to your home, every glass of water you have safely drunk, and every bank transfer that has gone through your phone. The instances of corporate malfeasance and harm are many, but the regulatory state has generally been successful at delivering safe and welfare-enhancing market transactions for producers and consumers.
Read your piece twice. Admit to some bewilderment! To me, preferences seem inevitable. On a very basic level, how do we appropriately control for them?
You have been busy! As a massive fan of binary classifications for machine-learning model building, I have to confess I found this manner of binary classification slightly disorienting and dystopian. Maybe that just means over my head…